
Algorithm? WHAT?
Weird topic but very important for every visuals.
This article will dive into the principles of algorithm design. If you haven’t a clue what I’m referring to, read on!
When you hear the word “algorithm,” you probably respond in one of three ways:
- You immediately know and understand what we’re talking about because you studied computer science.
- You know that algorithms are the workhorses of companies like Google and Facebook, but you aren’t really sure what the word means.
- You run and hide in fear because everything you know about algorithms reminds you of high-school Calculus nightmares.
If you are one of the second two, this article is for you.
Yes, Thanks To code.tutsplus.com for their contribution.
What is an Algorithm, Exactly?
Algorithms are not a special type of operation, necessarily. They are conceptual, a set of steps that you take in code to reach a specific goal.
Algorithms have been commonly defined in simple terms as “instructions for completing a task”. They’ve also been called “recipes”. In The Social Network, an algorithm is what Zuckerberg needed to make Facemash work. If you saw the movie, you probably remember seeing what looked like a scribbly equation on a window in Mark’s dorm room. But what does that scribbly algebra have to do with Mark’s simple “hot or not” site?
Algorithms are indeed instructions. Perhaps a more accurate description would be that algorithms are patterns for completing a task in an efficient way. Zuckerberg’s Facemash was a voting site to determine someone’s attractiveness relative to a whole group of people, but the user would only be given options between two people. Mark Zuckerberg needed an algorithm that decided which people to match up to one another, and how to value a vote relative to that person’s previous history and previous contenders. This required more intuition than simply counting votes for each person.
For instance, let’s say you wanted to create an algorithm for adding 1 to any negative number, and subtracting 1 from any positive number, and doing nothing to 0. You might do something like this (in JavaScript-esque pseudo code):
|
1
2
3
4
5
6
7
8
9
|
function addOrSubtractOne(number){ if (number < 0) { return number + 1 } else if (number < 0) { return number - 1 } else if (number == 0) { return 0; }} |
You may be saying to yourself, “That’s a function.” And you’re right. Algorithms are not a special type of operation, necessarily. They are conceptual – a set of steps that you take in code to reach a specific goal.
So why are they a big deal? Clearly, adding or subtracting 1 to a number is a fairly simple thing to do.
But let’s talk for a second about searching. To search for a number in an array of numbers, how would you think to do it? A naive approach would be to iterate the number, checking each number against the one you’re searching for. But this isn’t an efficient solution, and has a very wide range of possible completion times, making it an erratic and unreliable search method when scaled to large search sets.
|
1
2
3
4
5
6
|
function naiveSearch(needle, haystack){ for (var i = 0; i < haystack.length; i++){ if (haystack[i] == needle) { return needle; } } return false;} |
Fortunately, we can do better than this for search.
Why is it Inefficient?
There is no better way to become a better algorithm designer than to have a deep understanding and appreciation for algorithms.
Let’s say your array has 50,000 entries, and you brute-force search (that is, search by iterating the full array). The entry you are searching for, in the best case scenario, will be the first entry in the 50,000-entry array. In the worst case scenario, however, the algorithm will take 50,000 times longer to complete than in the best case scenario.
So what’s Better?
Instead, you would search using binary search. This involves sorting the array (which I will let you learn about on your own) and subsequently dividing the array in half, and checking to see if the search number is greater or less than the halfway mark in the array. If it is greater than the halfway mark of a sorted array, then we know that the first half can be discarded, as the searched number isn’t a part of the array. We can also cut out a lot of work by defining the outer bounds of the array and checking to see if the searched number exists outside of those bounds, and if so, we have taken what would have been a multiple-iteration operation and turned it into a single iteration operation (which in the brute-force algorithm would have taken 50,000 operations).
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
|
sortedHaystack = recursiveSort(haystack);function bSearch(needle, sortedHaystack, firstIteration){ if (firstIteration){ if (needle > sortedHaystack.last || needle < sortedHaystack.first){ return false; } } if (haystack.length == 2){ if (needle == haystack[0]) { return haystack[0]; } else { return haystack[1]; } } if (needle < haystack[haystack.length/2]){ bSearch(needle, haystack[0..haystack.length/2 -1], false); } else { bSearch(needle, haystack[haystack.length/2..haystack.length], false); }} |
Sounds Fairly Complicated
Take the seemingly complicated nature of a single binary search algorithm, and apply it to billions of possible links (as searching through Google). Beyond that, let’s apply some sort of ranking system to those linked searches to give an order of response pages. Better yet, apply some kind of seemingly randomized “suggestion” system based on artificial intelligence social models designed to identify who you might want to add as a friend.
This gives us a much clearer understanding of why algorithms are more than just a fancy name for functions. At their finest, they are clever, efficient ways of doing something that requires a higher level of intuition than the most apparent solution. They can take what might would require a supercomputer years to do and turn it into a task that finishes in seconds on a mobile phone.
How do Algorithms Apply to Me?
For most of us as developers, we aren’t designing high-level abstracted algorithms on a daily basis.
Luckily, we stand on the shoulders of the developers who came before us, who wrote native sort functions and allow us to search strings for substrings with indexOf in an efficient manner.
But we DO, however, deal with algorithms of our own. We create for loops and write functions every day; so how can good algorithm design principles inform the writing of these functions?
Know Your Input
One of the main principles of algorithmic design is to, if possible, build your algorithm in such a way that the input itself does some of the work for you. For instance, if you know that your input is always going to be numbers, you do not need to have exceptions/checks for strings, or coerce your values into numbers. If you know that your DOM element is the same every time in a for loop in JavaScript, you shouldn’t be querying for that element in every iteration. On the same token, in your for loops, you shouldn’t use convenience functions with overhead if you can accomplish the same thing using (closer to) simple operations.
|
01
02
03
04
05
06
07
08
09
10
11
12
|
// don't do this:for (var i = 1000; i > 0; i--){ $("#foo").append("<span>bar</span>");}// do this insteadvar foo = $("#foo");var s = "";for(var i = 1000; i > 0; i--){ s += "<span>bar</span>";}foo.append(s); |
If you are a JavaScript developer (and you use jQuery) and you don’t know what the above functions are doing and how they are significantly different, the next point is for you.
Understand Your Tools
At their finest, [algorithms] are clever, efficient ways of doing something that requires a higher level of intuition than the most apparent solution.
It is easy to think that this goes without saying. However, there is a difference between “knowing how to write jQuery” and “understanding jQuery”. Understanding your tools means that you understand what each line of code does, both immediately (the return value of a function or the effect of a method) and implicitly (how much overhead is associated with running a library function, or which is the most efficient method for concatenating a string). To write great algorithms, it is important to know the performance of lower-level functions or utilities, not just the name and implementation of them.
Understand the Environment
Designing efficient algorithms is a full-engagement undertaking. Beyond understanding your tools as a standalone piece, you must also understand the way that they interact with the larger system at hand. For instance, to understand JavaScript in a specific application entirely, it is important to understand the DOM and performance of JavaScript in cross browser scenarios, how available memory affects rendering speeds, the structure of servers (and their responses) you may be interacting with, as well as a myriad of other considerations that are intangible, such as usage scenarios.
Reducing the Workload
In general, the goal of algorithm design is to complete a job in fewer steps. (There are some exceptions, such as Bcrypt hashing.) When you write your code, take into consideration all of the simple operations the computer is taking to reach the goal. Here is a simple checklist to get started on a path to more efficient algorithm design:
- Use language features to reduce operations (variable caching, chaining, etc).
- Reduce iterative loop nesting as much as possible.
- Define variables outside of loops when possible.
- Use automatic loop indexing (if available) instead of manual indexing.
- Use clever reduction techniques, such as recursive divide and conquer and query optimization, to minimize the size of recursive processes.
Study Advanced Techniques
There is no better way to become a better algorithm designer than to have a deep understanding and appreciation for algorithms.
- Take an hour or two every week and read The Art of Computer Programming.
- Try a Facebook Programming Challenge or a Google Codejam.
- Learn to solve the same problem with different algorithmic techniques.
- Challenge yourself by implementing built in functions of a language, like
.sort(), with lower level operations.
How Do Algorithms Work?
Let’s take a closer look at an example.
A very simple example of an algorithm would be to find the largest number in an unsorted list of numbers. If you were given a list of five different numbers, you would have this figured out in no time, no computer needed. Now, how about five million different numbers? Clearly, you are going to need a computer to do this, and a computer needs an algorithm.
Below is what the algorithm could look like. Let’s say the input consists of a list of numbers, and this list is called L. The number L1 would be the first number in the list, L2 the second number, etc. And we know the list is not sorted – otherwise, the answer would be really easy. So, the input to the algorithm is a list of numbers, and the output should be the largest number in the list.
The algorithm would look something like this:
Step 1: Let Largest = L1
This means you start by assuming that the first number is the largest number.
Step 2: For each item in the list:
This means you will go through the list of numbers one by one.
Step 3: If the item > Largest:
If you find a new largest number, move to step four. If not, go back to step two, which means you move on to the next number in the list.
Step 4: Then Largest = the item
This replaces the old largest number with the new largest number you just found. Once this is completed, return to step two until there are no more numbers left in the list.
Step 5: Return Largest
This produces the desired result.
Notice that the algorithm is described as a series of logical steps in a language that is easily understood. For a computer to actually use these instructions, they need to be written in a language that a computer can understand, known as a programming language.
Now, Is The Next Gen.
Code-Dependent: Pros and Cons of the Algorithm Age
Algorithms are aimed at optimizing everything. They can save lives, make things easier and conquer chaos. Still, experts worry they can also put too much control in the hands of corporations and governments, perpetuate bias, create filter bubbles, cut choices, creativity and serendipity, and could result in greater unemployment

Algorithms are instructions for solving a problem or completing a task. Recipes are algorithms, as are math equations. Computer code is algorithmic. The internet runs on algorithms and all online searching is accomplished through them. Email knows where to go thanks to algorithms. Smartphone apps are nothing but algorithms. Computer and video games are algorithmic storytelling. Online dating and book-recommendation and travel websites would not function without algorithms. GPS mapping systems get people from point A to point B via algorithms. Artificial intelligence (AI) is naught but algorithms. The material people see on social media is brought to them by algorithms. In fact, everything people see and do on the web is a product of algorithms. Every time someone sorts a column in a spreadsheet, algorithms are at play, and most financial transactions today are accomplished by algorithms. Algorithms help gadgets respond to voice commands, recognize faces, sort photos and build and drive cars. Hacking, cyberattacks and cryptographic code-breaking exploit algorithms. Self-learning and self-programming algorithms are now emerging, so it is possible that in the future algorithms will write many if not most algorithms.
Algorithms are often elegant and incredibly useful tools used to accomplish tasks. They are mostly invisible aids, augmenting human lives in increasingly incredible ways. However, sometimes the application of algorithms created with good intentions leads to unintended consequences. Recent news items tie to these concerns:
- The British pound dropped 6.1% in value in seconds on Oct. 7, 2016, partly because of currency trades triggered by algorithms.
- Microsoft engineers created a Twitter bot named “Tay” this past spring in an attempt to chat with Millennials by responding to their prompts, but within hours it was spouting racist, sexist, Holocaust-denying tweets based on algorithms that had it “learning” how to respond to others based on what was tweeted at it.
- Facebook tried to create a feature to highlight Trending Topics from around the site in people’s feeds. First, it had a team of humans edit the feature, but controversy erupted when some accused the platform of being biased against conservatives. So, Facebook then turned the job over to algorithms only to find that they could not discern real news from fake news.
- Cathy O’Neil, author of Weapons of Math Destruction: How Big Data Increases Inequality and Threatens Democracy, pointed out that predictive analytics based on algorithms tend to punish the poor, using algorithmic hiring practices as an example.
- Well-intentioned algorithms can be sabotaged by bad actors. An internet slowdown swept the East Coast of the U.S. on Oct. 21, 2016, after hackers bombarded Dyn DNS, an internet traffic handler, with information that overloaded its circuits, ushering in a new era of internet attacks powered by internet-connected devices. This after internet security expert Bruce Schneier warned in September that “Someone Is Learning How to Take Down the Internet.” And the abuse of Facebook’s News Feed algorithm and general promulgation of fake news online became controversial as the 2016 U.S. presidential election proceeded.
- Researcher Andrew Tutt called for an “FDA for Algorithms,” noting, “The rise of increasingly complex algorithms calls for critical thought about how to best prevent, deter and compensate for the harms that they cause …. Algorithmic regulation will require federal uniformity, expert judgment, political independence and pre-market review to prevent – without stifling innovation – the introduction of unacceptably dangerous algorithms into the market.”
- The White House released two reports in October 2016 detailing the advance of algorithms and artificial intelligence and plans to address issues tied to it, and it issued a December report outlining some of the potential effects of AI-driven automation on the U.S. job market and economy.
- On January 17, 2017, the Future of Life Institute published a list of 23 Principles for Beneficial Artificial Intelligence, created by a gathering of concerned researchers at a conference at Asimolar, in Pacific Grove, California. The more than 1,600 signatories included Steven Hawking, Elon Musk, Ray Kurzweil and hundreds of the world’s foremost AI researchers.
The use of algorithms is spreading as massive amounts of data are being created, captured and analyzed by businesses and governments. Some are calling this the Age of Algorithms and predicting that the future of algorithms is tied to machine learning and deep learning that will get better and better at an ever-faster pace.
While many of the 2016 U.S. presidential election post-mortems noted the revolutionary impact of web-based tools in influencing its outcome, XPrize Foundation CEO Peter Diamandis predicted that “five big tech trends will make this election look tame.” He said advances in quantum computing and the rapid evolution of AI and AI agents embedded in systems and devices in the Internet of Things will lead to hyper-stalking, influencing and shaping of voters, and hyper-personalized ads, and will create new ways to misrepresent reality and perpetuate falsehoods.
 Analysts like Aneesh Aneesh of Stanford University foresee algorithms taking over public and private activities in a new era of “algocratic governance” that supplants “bureaucratic hierarchies.” Others, like Harvard’s Shoshana Zuboff, describe the emergence of “surveillance capitalism” that organizes economic behavior in an “information civilization.”
Analysts like Aneesh Aneesh of Stanford University foresee algorithms taking over public and private activities in a new era of “algocratic governance” that supplants “bureaucratic hierarchies.” Others, like Harvard’s Shoshana Zuboff, describe the emergence of “surveillance capitalism” that organizes economic behavior in an “information civilization.”
To illuminate current attitudes about the potential impacts of algorithms in the next decade, Pew Research Center and Elon University’s Imagining the Internet Center conducted a large-scale canvassing of technology experts, scholars, corporate practitioners and government leaders. Some 1,302 responded to this question about what will happen in the next decade:
Will the net overall effect of algorithms be positive for individuals and society or negative for individuals and society?
The non-scientific canvassing found that 38% of these particular respondents predicted that the positive impacts of algorithms will outweigh negatives for individuals and society in general, while 37% said negatives will outweigh positives; 25% said the overall impact of algorithms will be about 50-50, positive-negative. [See “About this canvassing of experts” for further details about the limits of this sample.]
Participants were asked to explain their answers, and most wrote detailed elaborations that provide insights about hopeful and concerning trends. Respondents were allowed to respond anonymously; these constitute a slight majority of the written elaborations. These findings do not represent all the points of view that are possible to a question like this, but they do reveal a wide range of valuable observations based on current trends.
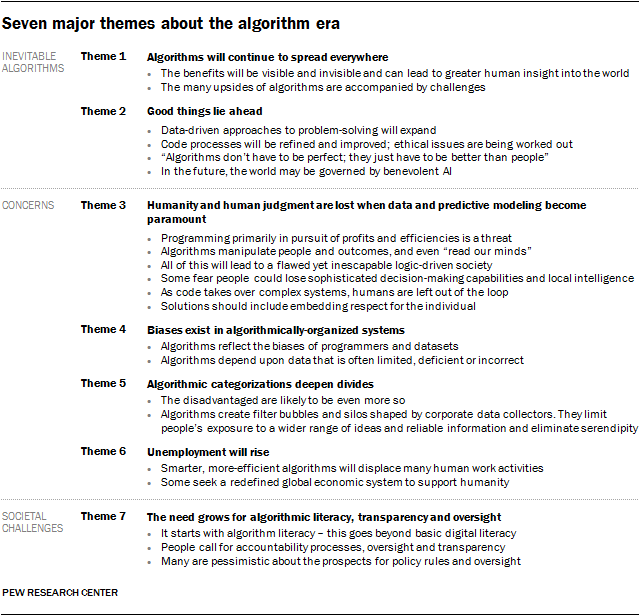
In the next section we offer a brief outline of seven key themes found among the written elaborations. Following that introductory section there is a much more in-depth look at respondents’ thoughts tied to each of the themes. All responses are lightly edited for style.
Theme 1: Algorithms will continue to spread everywhere
There is fairly uniform agreement among these respondents that algorithms are generally invisible to the public and there will be an exponential rise in their influence in the next decade.
A representative statement of this view came from Barry Chudakov, founder and principal at Sertain Research and StreamFuzion Corp. He replied:
“‘If every algorithm suddenly stopped working, it would be the end of the world as we know it.’ (Pedro Domingo’s The Master Algorithm). Fact: We have already turned our world over to machine learning and algorithms. The question now is, how to better understand and manage what we have done?
“Algorithms are a useful artifact to begin discussing the larger issue of the effects of technology-enabled assists in our lives. Namely, how can we see them at work? Consider and assess their assumptions? And most importantly for those who don’t create algorithms for a living – how do we educate ourselves about the way they work, where they are in operation, what assumptions and biases are inherent in them, and how to keep them transparent? Like fish in a tank, we can see them swimming around and keep an eye on them.
Fact: We have already turned our world over to machine learning and algorithms. The question now is, how to better understand and manage what we have done?
BARRY CHUDAKOV
“Algorithms are the new arbiters of human decision-making in almost any area we can imagine, from watching a movie (Affectiva emotion recognition) to buying a house (Zillow.com) to self-driving cars (Google). Deloitte Global predicted more than 80 of the world’s 100 largest enterprise software companies will have cognitive technologies – mediated by algorithms – integrated into their products by the end of 2016. As Brian Christian and Tom Griffiths write in Algorithms to Live By, algorithms provide ‘a better standard against which to compare human cognition itself.’ They are also a goad to consider that same cognition: How are we thinking and what does it mean to think through algorithms to mediate our world?
“The main positive result of this is better understanding of how to make rational decisions, and in this measure a better understanding of ourselves. After all, algorithms are generated by trial and error, by testing, by observing, and coming to certain mathematical formulae regarding choices that have been made again and again – and this can be used for difficult choices and problems, especially when intuitively we cannot readily see an answer or a way to resolve the problem. The 37% Rule, optimal stopping and other algorithmic conclusions are evidence-based guides that enable us to use wisdom and mathematically verified steps to make better decisions.
“The secondary positive result is connectivity. In a technological recapitulation of what spiritual teachers have been saying for centuries, our things are demonstrating that everything is – or can be – connected to everything else. Algorithms with the persistence and ubiquity of insects will automate processes that used to require human manipulation and thinking. These can now manage basic processes of monitoring, measuring, counting or even seeing. Our car can tell us to slow down. Our televisions can suggest movies to watch. A grocery can suggest a healthy combination of meats and vegetables for dinner. Siri reminds you it’s your anniversary.
“The main negative changes come down to a simple but now quite difficult question: How can we see, and fully understand the implications of, the algorithms programmed into everyday actions and decisions? The rub is this: Whose intelligence is it, anyway? … Our systems do not have, and we need to build in, what David Gelernter called ‘topsight,’ the ability to not only create technological solutions but also see and explore their consequences before we build business models, companies and markets on their strengths, and especially on their limitations.”
Chudakov added that this is especially necessary because in the next decade and beyond, “By expanding collection and analysis of data and the resulting application of this information, a layer of intelligence or thinking manipulation is added to processes and objects that previously did not have that layer. So prediction possibilities follow us around like a pet. The result: As information tools and predictive dynamics are more widely adopted, our lives will be increasingly affected by their inherent conclusions and the narratives they spawn.”
“The overall impact of ubiquitous algorithms is presently incalculable because the presence of algorithms in everyday processes and transactions is now so great, and is mostly hidden from public view. All of our extended thinking systems (algorithms fuel the software and connectivity that create extended thinking systems) demand more thinking – not less – and a more global perspective than we have previously managed. The expanding collection and analysis of data and the resulting application of this information can cure diseases, decrease poverty, bring timely solutions to people and places where need is greatest, and dispel millennia of prejudice, ill-founded conclusions, inhumane practice and ignorance of all kinds. Our algorithms are now redefining what we think, how we think and what we know. We need to ask them to think about their thinking – to look out for pitfalls and inherent biases before those are baked in and harder to remove.
“To create oversight that would assess the impact of algorithms, first we need to see and understand them in the context for which they were developed. That, by itself, is a tall order that requires impartial experts backtracking through the technology development process to find the models and formulae that originated the algorithms. Then, keeping all that learning at hand, the experts need to soberly assess the benefits and deficits or risks the algorithms create. Who is prepared to do this? Who has the time, the budget and resources to investigate and recommend useful courses of action? This is a 21st-century job description – and market niche – in search of real people and companies. In order to make algorithms more transparent, products and product information circulars might include an outline of algorithmic assumptions, akin to the nutritional sidebar now found on many packaged food products, that would inform users of how algorithms drive intelligence in a given product and a reasonable outline of the implications inherent in those assumptions.”
Theme 2: Good things lie ahead
A number of respondents noted the many ways in which algorithms will help make sense of massive amounts of data, noting that this will spark breakthroughs in science, new conveniences and human capacities in everyday life, and an ever-better capacity to link people to the information that will help them. They perform seemingly miraculous tasks humans cannot and they will continue to greatly augment human intelligence and assist in accomplishing great things. A representative proponent of this view is Stephen Downes, a researcher at the National Research Council of Canada, who listed the following as positive changes:
“Some examples:
Banks. Today banks provide loans based on very incomplete data. It is true that many people who today qualify for loans would not get them in the future. However, many people – and arguably many more people – will be able to obtain loans in the future, as banks turn away from using such factors as race, socio-economic background, postal code and the like to assess fit. Moreover, with more data (and with a more interactive relationship between bank and client) banks can reduce their risk, thus providing more loans, while at the same time providing a range of services individually directed to actually help a person’s financial state.
“Health care providers. Health care is a significant and growing expense not because people are becoming less healthy (in fact, society-wide, the opposite is true) but because of the significant overhead required to support increasingly complex systems, including prescriptions, insurance, facilities and more. New technologies will enable health providers to shift a significant percentage of that load to the individual, who will (with the aid of personal support systems) manage their health better, coordinate and manage their own care, and create less of a burden on the system. As the overall cost of health care declines, it becomes increasingly feasible to provide single-payer health insurance for the entire population, which has known beneficial health outcomes and efficiencies.
“Governments. A significant proportion of government is based on regulation and monitoring, which will no longer be required with the deployment of automated production and transportation systems, along with sensor networks. This includes many of the daily (and often unpleasant) interactions we have with government today, from traffic offenses, manifestation of civil discontent, unfair treatment in commercial and legal processes, and the like. A simple example: One of the most persistent political problems in the United States is the gerrymandering of political boundaries to benefit incumbents. Electoral divisions created by an algorithm to a large degree eliminate gerrymandering (and when open and debatable, can be modified to improve on that result).”
A sampling of additional answers, from anonymous respondents:
The efficiencies of algorithms will lead to more creativity and self-expression.
- “Algorithms find knowledge in an automated way much faster than traditionally feasible.”
- “Algorithms can crunch databases quickly enough to alleviate some of the red tape and bureaucracy that currently slows progress down.”
- “We will see less pollution, improved human health, less economic waste.”
- “Algorithms have the potential to equalize access to information.”
- “The efficiencies of algorithms will lead to more creativity and self-expression.”
- “Algorithms can diminish transportation issues; they can identify congestion and alternative times and paths.”
- “Self-driving cars could dramatically reduce the number of accidents we have per year, as well as improve quality of life for most people.”
- “Better-targeted delivery of news, services and advertising.”
- “More evidence-based social science using algorithms to collect data from social media and click trails.”
- “Improved and more proactive police work, targeting areas where crime can be prevented.”
- “Fewer underdeveloped areas and more international commercial exchanges.”
- “Algorithms ease the friction in decision-making, purchasing, transportation and a large number of other behaviors.”
- “Bots will follow orders to buy your stocks. Digital agents will find the materials you need.”
- “Any errors could be corrected. This will mean the algorithms only become more efficient to humanity’s desires as time progresses.”
Themes illuminating concerns and challenges
Participants in this study were in substantial agreement that the abundant positives of accelerating code-dependency will continue to drive the spread of algorithms; however, as with all great technological revolutions, this trend has a dark side. Most respondents pointed out concerns, chief among them the final five overarching themes of this report; all have subthemes.
Theme 3: Humanity and human judgment are lost when data and predictive modeling become paramount
Advances in algorithms are allowing technology corporations and governments to gather, store, sort and analyze massive data sets. Experts in this canvassing noted that these algorithms are primarily written to optimize efficiency and profitability without much thought about the possible societal impacts of the data modeling and analysis. These respondents argued that humans are considered to be an “input” to the process and they are not seen as real, thinking, feeling, changing beings. They say this is creating a flawed, logic-driven society and that as the process evolves – that is, as algorithms begin to write the algorithms – humans may get left out of the loop, letting “the robots decide.” Representative of this view:
Bart Knijnenburg, assistant professor in human-centered computing at Clemson University, replied, “Algorithms will capitalize on convenience and profit, thereby discriminating [against] certain populations, but also eroding the experience of everyone else. The goal of algorithms is to fit some of our preferences, but not necessarily all of them: They essentially present a caricature of our tastes and preferences. My biggest fear is that, unless we tune our algorithms for self-actualization, it will be simply too convenient for people to follow the advice of an algorithm (or, too difficult to go beyond such advice), turning these algorithms into self-fulfilling prophecies, and users into zombies who exclusively consume easy-to-consume items.”
An anonymous futurist said, “This has been going on since the beginning of the industrial revolution. Every time you design a human system optimized for efficiency or profitability you dehumanize the workforce. That dehumanization has now spread to our health care and social services. When you remove the humanity from a system where people are included, they become victims.”
Another anonymous respondent wrote, “We simply can’t capture every data element that represents the vastness of a person and that person’s needs, wants, hopes, desires. Who is collecting what data points? Do the human beings the data points reflect even know or did they just agree to the terms of service because they had no real choice? Who is making money from the data? How is anyone to know how his/her data is being massaged and for what purposes to justify what ends? There is no transparency, and oversight is a farce. It’s all hidden from view. I will always remain convinced the data will be used to enrich and/or protect others and not the individual. It’s the basic nature of the economic system in which we live.”
A sampling of excerpts tied to this theme from other respondents (for details, read the fuller versions in the full report):
Algorithms have the capability to shape individuals’ decisions without them even knowing it, giving those who have control of the algorithms an unfair position of power.
- “The potential for good is huge, but the potential for misuse and abuse – intentional, and inadvertent – may be greater.”
- “Companies seek to maximize profit, not maximize societal good. Worse, they repackage profit-seeking as a societal good. We are nearing the crest of a wave, the trough side of which is a new ethics of manipulation, marketing, nearly complete lack of privacy.”
- “What we see already today is that, in practice, stuff like ‘differential pricing’ does not help the consumer; it helps the company that is selling things, etc.”
- “Individual human beings will be herded around like cattle, with predictably destructive results on rule of law, social justice and economics.”
- “There is an incentive only to further obfuscate the presence and operations of algorithmic shaping of communications processes.”
- “Algorithms are … amplifying the negative impacts of data gaps and exclusions.”
- “Algorithms have the capability to shape individuals’ decisions without them even knowing it, giving those who have control of the algorithms an unfair position of power.”
- “The fact the internet can, through algorithms, be used to almost read our minds means [that] those who have access to the algorithms and their databases have a vast opportunity to manipulate large population groups.”
- “The lack of accountability and complete opacity is frightening.”
- “By utilitarian metrics, algorithmic decision-making has no downside; the fact that it results in perpetual injustices toward the very minority classes it creates will be ignored. The Common Good has become a discredited, obsolete relic of The Past.”
- “In an economy increasingly dominated by a tiny, very privileged and insulated portion of the population, it will largely reproduce inequality for their benefit. Criticism will be belittled and dismissed because of the veneer of digital ‘logic’ over the process.”
- “Algorithms are the new gold, and it’s hard to explain why the average ‘good’ is at odds with the individual ‘good.’”
- “We will interpret the negative individual impact as the necessary collateral damage of ‘progress.’”
- “This will kill local intelligence, local skills, minority languages, local entrepreneurship because most of the available resources will be drained out by the global competitors.”
- “Algorithms in the past have been created by a programmer. In the future they will likely be evolved by intelligent/learning machines …. Humans will lose their agency in the world.”
- “It will only get worse because there’s no ‘crisis’ to respond to, and hence, not only no motivation to change, but every reason to keep it going – especially by the powerful interests involved. We are heading for a nightmare.”
- “Web 2.0 provides more convenience for citizens who need to get a ride home, but at the same time – and it’s naive to think this is a coincidence – it’s also a monetized, corporatized, disempowering, cannibalizing harbinger of the End Times. (I exaggerate for effect. But not by much.)”
Theme 4: Biases exist in algorithmically-organized systems
Two strands of thinking tie together here. One is that the algorithm creators (code writers), even if they strive for inclusiveness, objectivity and neutrality, build into their creations their own perspectives and values. The other is that the datasets to which algorithms are applied have their own limits and deficiencies. Even datasets with billions of pieces of information do not capture the fullness of people’s lives and the diversity of their experiences. Moreover, the datasets themselves are imperfect because they do not contain inputs from everyone or a representative sample of everyone. The two themes are advanced in these answers:
Justin Reich, executive director at the MIT Teaching Systems Lab, observed, “The algorithms will be primarily designed by white and Asian men – with data selected by these same privileged actors – for the benefit of consumers like themselves. Most people in positions of privilege will find these new tools convenient, safe and useful. The harms of new technology will be most experienced by those already disadvantaged in society, where advertising algorithms offer bail bondsman ads that assume readers are criminals, loan applications that penalize people for proxies so correlated with race that they effectively penalize people based on race, and similar issues.”
Dudley Irish, a software engineer, observed, “All, let me repeat that, all of the training data contains biases. Much of it either racial- or class-related, with a fair sprinkling of simply punishing people for not using a standard dialect of English. To paraphrase Immanuel Kant, out of the crooked timber of these datasets no straight thing was ever made.”
A sampling of quote excerpts tied to this theme from other respondents (for details, read the fuller versions in the full report):
One of the greatest challenges of the next era will be balancing protection of intellectual property in algorithms with protecting the subjects of those algorithms from unfair discrimination and social engineering.
- “Algorithms are, by definition, impersonal and based on gross data and generalized assumptions. The people writing algorithms, even those grounded in data, are a non-representative subset of the population.”
- “If you start at a place of inequality and you use algorithms to decide what is a likely outcome for a person/system, you inevitably reinforce inequalities.”
- “We will all be mistreated as more homogenous than we are.”
- “The result could be the institutionalization of biased and damaging decisions with the excuse of, ‘The computer made the decision, so we have to accept it.’”
- “The algorithms will reflect the biased thinking of people. Garbage in, garbage out. Many dimensions of life will be affected, but few will be helped. Oversight will be very difficult or impossible.”
- “Algorithms value efficiency over correctness or fairness, and over time their evolution will continue the same priorities that initially formulated them.”
- “One of the greatest challenges of the next era will be balancing protection of intellectual property in algorithms with protecting the subjects of those algorithms from unfair discrimination and social engineering.”
- “Algorithms purport to be fair, rational and unbiased but just enforce prejudices with no recourse.”
- “Unless the algorithms are essentially open source and as such can be modified by user feedback in some fair fashion, the power that likely algorithm-producers (corporations and governments) have to make choices favorable to themselves, whether in internet terms of service or adhesion contracts or political biases, will inject both conscious and unconscious bias into algorithms.”
Theme 5: Algorithmic categorizations deepen divides
Two connected ideas about societal divisions were evident in many respondents’ answers. First, they predicted that an algorithm-assisted future will widen the gap between the digitally savvy (predominantly the most well-off, who are the most desired demographic in the new information ecosystem) and those who are not nearly as connected or able to participate. Second, they said social and political divisions will be abetted by algorithms, as algorithm-driven categorizations and classifications steer people into echo chambers of repeated and reinforced media and political content. Two illustrative answers:
Ryan Hayes, owner of Fit to Tweet, commented, “Twenty years ago we talked about the ‘digital divide’ being people who had access to a computer at home vs. those that didn’t, or those who had access to the internet vs. those who didn’t …. Ten years from now, though, the life of someone whose capabilities and perception of the world is augmented by sensors and processed with powerful AI and connected to vast amounts of data is going to be vastly different from that of those who don’t have access to those tools or knowledge of how to utilize them. And that divide will be self-perpetuating, where those with fewer capabilities will be more vulnerable in many ways to those with more.”
Adam Gismondi, a visiting scholar at Boston College, wrote, “I am fearful that as users are quarantined into distinct ideological areas, human capacity for empathy may suffer. Brushing up against contrasting viewpoints challenges us, and if we are able to (actively or passively) avoid others with different perspectives, it will negatively impact our society. It will be telling to see what features our major social media companies add in coming years, as they will have tremendous power over the structure of information flow.”
A sampling of quote excerpts tied to this theme from other respondents (for details, read the fuller versions in the full report):
The overall effect will be positive for some individuals. It will be negative for the poor and the uneducated. As a result, the digital divide and wealth disparity will grow. It will be a net negative for society.
- “If the current economic order remains in place, then I do not see the growth of data-driven algorithms providing much benefit to anyone outside of the richest in society.”
- “Social inequalities will presumably become reified.”
- “The major risk is that less-regular users, especially those who cluster on one or two sites or platforms, won’t develop that navigational and selection facility and will be at a disadvantage.”
- “Algorithms make discrimination more efficient and sanitized. Positive impact will be increased profits for organizations able to avoid risk and costs. Negative impacts will be carried by all deemed by algorithms to be risky or less profitable.”
- “Society will be stratified by which trust/identity provider one can afford/qualify to go with. The level of privacy and protection will vary. Lois McMaster [Bujold]’s Jackson’s Whole suddenly seems a little more chillingly realistic.”
- “We have radically divergent sets of values, political and other, and algos are always rooted in the value systems of their creators. So the scenario is one of a vast opening of opportunity – economic and otherwise – under the control of either the likes of Zuckerberg or the grey-haired movers of global capital or ….”
- “The overall effect will be positive for some individuals. It will be negative for the poor and the uneducated. As a result, the digital divide and wealth disparity will grow. It will be a net negative for society.”
- “Racial exclusion in consumer targeting. Gendered exclusion in consumer targeting. Class exclusion in consumer targeting …. Nationalistic exclusion in consumer targeting.”
- “If the algorithms directing news flow suppress contradictory information – information that challenges the assumptions and values of individuals – we may see increasing extremes of separation in worldviews among rapidly diverging subpopulations.”
- “We may be heading for lowest-common-denominator information flows.”
- “Efficiency and the pleasantness and serotonin that come from prescriptive order are highly overrated. Keeping some chaos in our lives is important.”
A number of participants in this canvassing expressed concerns over the change in the public’s information diets, the “atomization of media,” an over-emphasis of the extreme, ugly, weird news, and the favoring of “truthiness” over more-factual material that may be vital to understanding how to be a responsible citizen of the world.
Theme 6: Unemployment will rise
The spread of artificial intelligence (AI) has the potential to create major unemployment and all the fallout from that.
An anonymous CEO said, “If a task can be effectively represented by an algorithm, then it can be easily performed by a machine. The negative trend I see here is that – with the rise of the algorithm – humans will be replaced by machines/computers for many jobs/tasks. What will then be the fate of Man?”
A sampling of quote excerpts tied to this theme from other respondents (for details, read the fuller versions in the full report):
I foresee algorithms replacing almost all workers with no real options for the replaced humans.
- “AI and robots are likely to disrupt the workforce to a potential 100% human unemployment. They will be smarter more efficient and productive and cost less, so it makes sense for corporations and business to move in this direction.”
- “The massive boosts in productivity due to automation will increase the disparity between workers and owners of capital.”
- “Modern Western society is built on a societal model whereby Capital is exchanged for Labour to provide economic growth. If Labour is no longer part of that exchange, the ramifications will be immense.”
- “No jobs, growing population and less need for the average person to function autonomously. Which part of this is warm and fuzzy?”
- “I foresee algorithms replacing almost all workers with no real options for the replaced humans.”
- “In the long run, it could be a good thing for individuals by doing away with low-value repetitive tasks and motivating them to perform ones that create higher value.”
- “Hopefully, countries will have responded by implementing forms of minimal guaranteed living wages and free education past K-12; otherwise the brightest will use online resources to rapidly surpass average individuals and the wealthiest will use their economic power to gain more political advantages.”
Theme 7: The need grows for algorithmic literacy, transparency and oversight
The respondents to this canvassing offered a variety of ideas about how individuals and the broader culture might respond to the algorithm-ization of life. They argued for public education to instill literacy about how algorithms function in the general public. They also noted that those who create and evolve algorithms are not held accountable to society and argued there should be some method by which they are. Representative comments:
Susan Etlinger, industry analyst at Altimeter Group, said, “Much like the way we increasingly wish to know the place and under what conditions our food and clothing are made, we should question how our data and decisions are made as well. What is the supply chain for that information? Is there clear stewardship and an audit trail? Were the assumptions based on partial information, flawed sources or irrelevant benchmarks? Did we train our data sufficiently? Were the right stakeholders involved, and did we learn from our mistakes? The upshot of all of this is that our entire way of managing organizations will be upended in the next decade. The power to create and change reality will reside in technology that only a few truly understand. So to ensure that we use algorithms successfully, whether for financial or human benefit or both, we need to have governance and accountability structures in place. Easier said than done, but if there were ever a time to bring the smartest minds in industry together with the smartest minds in academia to solve this problem, this is the time.”
Chris Kutarna, author of Age of Discovery and fellow at the Oxford Martin School, wrote, “Algorithms are an explicit form of heuristic, a way of routinizing certain choices and decisions so that we are not constantly drinking from a fire hydrant of sensory inputs. That coping strategy has always been co-evolving with humanity, and with the complexity of our social systems and data environments. Becoming explicitly aware of our simplifying assumptions and heuristics is an important site at which our intellects and influence mature. What is different now is the increasing power to program these heuristics explicitly, to perform the simplification outside of the human mind and within the machines and platforms that deliver data to billions of individual lives. It will take us some time to develop the wisdom and the ethics to understand and direct this power. In the meantime, we honestly don’t know how well or safely it is being applied. The first and most important step is to develop better social awareness of who, how, and where it is being applied.”
A sampling of quote excerpts tied to this theme from other respondents (for details, read the fuller versions in the full report):
We need some kind of rainbow coalition to come up with rules to avoid allowing inbuilt bias and groupthink to effect the outcomes.
- “Who guards the guardians? And, in particular, which ‘guardians’ are doing what, to whom, using the vast collection of information?”
- “There are no incentives in capitalism to fight filter bubbles, profiling, and the negative effects, and governmental/international governance is virtually powerless.”
- “Oversight mechanisms might include stricter access protocols; sign off on ethical codes for digital management and named stewards of information; online tracking of an individual’s reuse of information; opt-out functions; setting timelines on access; no third-party sale without consent.”
- “Unless there is an increased effort to make true information literacy a part of basic education, there will be a class of people who can use algorithms and a class used by algorithms.”
- “Consumers have to be informed, educated, and, indeed, activist in their orientation toward something subtle. This is what computer literacy is about in the 21st century.”
- “Finding a framework to allow for transparency and assess outcomes will be crucial. Also a need to have a broad understanding of the algorithmic ‘value chain’ and that data is the key driver and as valuable as the algorithm which it trains.”
- “Algorithmic accountability is a big-tent project, requiring the skills of theorists and practitioners, lawyers, social scientists, journalists, and others. It’s an urgent, global cause with committed and mobilized experts looking for support.”
- “Eventually, software liability law will be recognized to be in need of reform, since right now, literally, coders can get away with murder.”
- “The Law of Unintended Consequences indicates that the increasing layers of societal and technical complexity encoded in algorithms ensure that unforeseen catastrophic events will occur – probably not the ones we were worrying about.”
- “Eventually we will evolve mechanisms to give consumers greater control that should result in greater understanding and trust …. The pushback will be inevitable but necessary and will, in the long run, result in balances that are more beneficial for all of us.”
- “We need some kind of rainbow coalition to come up with rules to avoid allowing inbuilt bias and groupthink to effect the outcomes.”
- “Algorithms are too complicated to ever be transparent or to ever be completely safe. These factors will continue to influence the direction of our culture.”
- “I expect meta-algorithms will be developed to try to counter the negatives of algorithms.”
Anonymous respondents shared these one-liners on the topic:
- “The golden rule: He who owns the gold makes the rules.”
- “The bad guys appear to be way ahead of the good guys.”
- “Resistance is futile.”
- “Algorithms are defined by people who want to sell you something (goods, services, ideologies) and will twist the results to favor doing so.”
- “Algorithms are surely helpful but likely insufficient unless combined with human knowledge and political will.”
Finally, this prediction from an anonymous participant who sees the likely endpoint to be one of two extremes:
“The overall impact will be utopia or the end of the human race; there is no middle ground foreseeable. I suspect utopia given that we have survived at least one existential crisis (nuclear) in the past and that our track record toward peace, although slow, is solid.”
Key experts’ thinking about the future impacts of algorithms
Following is a brief collection of comments by several of the many top analysts who participated in this canvassing:
‘Steering people to useful information’
Vinton Cerf, Internet Hall of Fame member and vice president and chief internet evangelist at Google: “Algorithms are mostly intended to steer people to useful information and I see this as a net positive.”
Beware ‘unverified, untracked, unrefined models’
Cory Doctorow, writer, computer science activist-in-residence at MIT Media Lab and co-owner of Boing Boing, responded, “The choices in this question are too limited. The right answer is, ‘If we use machine learning models rigorously, they will make things better; if we use them to paper over injustice with the veneer of machine empiricism, it will be worse.’ Amazon uses machine learning to optimize its sales strategies. When they make a change, they make a prediction about its likely outcome on sales, then they use sales data from that prediction to refine the model. Predictive sentencing scoring contractors to America’s prison system use machine learning to optimize sentencing recommendation. Their model also makes predictions about likely outcomes (on reoffending), but there is no tracking of whether their model makes good predictions, and no refinement. This frees them to make terrible predictions without consequence. This characteristic of unverified, untracked, unrefined models is present in many places: terrorist watchlists; drone-killing profiling models; modern redlining/Jim Crow systems that limit credit; predictive policing algorithms; etc. If we mandate, or establish normative limits, on practices that correct this sleazy conduct, then we can use empiricism to correct for bias and improve the fairness and impartiality of firms and the state (and public/private partnerships). If, on the other hand, the practice continues as is, it terminates with a kind of Kafkaesque nightmare where we do things ‘because the computer says so’ and we call them fair ‘because the computer says so.’”
‘A general trend toward positive outcomes will prevail’
Jonathan Grudin, principal researcher at Microsoft, said, “We are finally reaching a state of symbiosis or partnership with technology. The algorithms are not in control; people create and adjust them. However, positive effects for one person can be negative for another, and tracing causes and effects can be difficult, so we will have to continually work to understand and adjust the balance. Ultimately, most key decisions will be political, and I’m optimistic that a general trend toward positive outcomes will prevail, given the tremendous potential upside to technology use. I’m less worried about bad actors prevailing than I am about unintended and unnoticed negative consequences sneaking up on us.”
‘Faceless systems more interested in surveillance and advertising than actual service’
Doc Searls, journalist, speaker and director of Project VRM at Harvard University’s Berkman Center, wrote, “The biggest issue with algorithms today is the black-box nature of some of the largest and most consequential ones. An example is the one used by Dun & Bradstreet to decide credit worthiness. The methods behind the decisions it makes are completely opaque, not only to those whose credit is judged, but to most of the people running the algorithm as well. Only the programmers are in a position to know for sure what the algorithm does, and even they might not be clear about what’s going on. In some cases there is no way to tell exactly why or how a decision by an algorithm is reached. And even if the responsible parties do know exactly how the algorithm works, they will call it a trade secret and keep it hidden. There is already pushback against the opacity of algorithms, and the sometimes vast systems behind them. Many lawmakers and regulators also want to see, for example, Google’s and Facebook’s vast server farms more deeply known and understood. These things have the size, scale, and in some ways the importance of nuclear power plants and oil refineries, yet enjoy almost no regulatory oversight. This will change. At the same time, so will the size of the entities using algorithms. They will get smaller and more numerous, as more responsibility over individual lives moves away from faceless systems more interested in surveillance and advertising than actual service.”
A call for #AlgorithmicTransparency
Marc Rotenberg, executive director of the Electronic Privacy Information Center, observed, “The core problem with algorithmic-based decision-making is the lack of accountability. Machines have literally become black boxes – even the developers and operators do not fully understand how outputs are produced. The problem is further exacerbated by ‘digital scientism’ (my phrase) – an unwavering faith in the reliability of big data. ‘Algorithmic transparency’ should be established as a fundamental requirement for all AI-based decision-making. There is a larger problem with the increase of algorithm-based outcomes beyond the risk of error or discrimination – the increasing opacity of decision-making and the growing lack of human accountability. We need to confront the reality that power and authority are moving from people to machines. That is why #AlgorithmicTransparency is one of the great challenges of our era.”
The data ‘will be misused in various ways’
Richard Stallman, Internet Hall of Fame member and president of the Free Software Foundation, said, “People will be pressured to hand over all the personal data that the algorithms would judge. The data, once accumulated, will be misused in various ways – by the companies that collect them, by rogue employees, by crackers that steal the data from the company’s site, and by the state via National Security Letters. I have heard that people who refuse to be used by Facebook are discriminated against in some ways. Perhaps soon they will be denied entry to the U.S., for instance. Even if the U.S. doesn’t actually do that, people will fear that it will. Compare this with China’s social obedience score for internet users.”
People must live with outcomes of algorithms ‘even though they are fearful of the risks’
David Clark, Internet Hall of Fame member and senior research scientist at MIT, replied, “I see the positive outcomes outweighing the negative, but the issue will be that certain people will suffer negative consequences, perhaps very serious, and society will have to decide how to deal with these outcomes. These outcomes will probably differ in character, and in our ability to understand why they happened, and this reality will make some people fearful. But as we see today, people feel that they must use the internet to be a part of society. Even if they are fearful of the consequences, people will accept that they must live with the outcomes of these algorithms, even though they are fearful of the risks.”
‘EVERY area of life will be affected. Every. Single. One.’
Baratunde Thurston, Director’s Fellow at MIT Media Lab, Fast Company columnist, and former digital director of The Onion, wrote: “Main positive changes: 1) The excuse of not knowing things will be reduced greatly as information becomes even more connected and complete. 2) Mistakes that result from errors in human judgment, ‘knowledge,’ or reaction time will be greatly reduced. Let’s call this the ‘robots drive better than people’ principle. Today’s drivers will whine, but in 50 years no one will want to drive when they can use that transportation time to experience a reality-indistinguishable immersive virtual environment filled with a bunch of Beyoncé bots.
“3) Corruption that exists today as a result of human deception will decline significantly—bribes, graft, nepotism. If the algorithms are built well and robustly, the opportunity to insert this inefficiency (e.g., hiring some idiot because he’s your cousin) should go down. 4) In general, we should achieve a much more efficient distribution of resources, including expensive (in dollars or environmental cost) resources like fossil fuels. Basically, algorithmic insight will start to affect the design of our homes, cities, transportation networks, manufacturing levels, waste management processing, and more. There’s a lot of redundancy in a world where every American has a car she never uses. We should become far more energy efficient once we reduce the redundancy of human-drafted processes.
“But there will be negative changes: 1) There will be an increased speed of interactions and volume of information processed—everything will get faster. None of the efficiency gains brought about by technology has ever lead to more leisure or rest or happiness. We will simply shop more, work more, decide more things because our capacity to do all those will have increased. It’s like adding lanes to the highway as a traffic management solution. When you do that, you just encourage more people to drive. The real trick is to not add more car lanes but build a world in which fewer people need or want to drive.
“2) There will be algorithmic and data-centric oppression. Given that these systems will be designed by demonstrably imperfect and biased human beings, we are likely to create new and far less visible forms of discrimination and oppression. The makers of these algorithms and the collectors of the data used to test and prime them have nowhere near a comprehensive understanding of culture, values, and diversity. They will forget to test their image recognition on dark skin or their medical diagnostic tools on Asian women or their transport models during major sporting events under heavy fog. We will assume the machines are smarter, but we will realize they are just as dumb as we are but better at hiding it.
“3) Entire groups of people will be excluded and they most likely won’t know about the parallel reality they don’t experience. Every area of life will be affected. Every. Single. One.”
A call for ‘industry reform’ and ‘more savvy regulatory regimes’
Technologist Anil Dash said, “The best parts of algorithmic influence will make life better for many people, but the worst excesses will truly harm the most marginalized in unpredictable ways. We’ll need both industry reform within the technology companies creating these systems and far more savvy regulatory regimes to handle the complex challenges that arise.”
‘We are a society that takes its life direction from the palm of our hands’
John Markoff, author of Machines of Loving Grace: The Quest for Common Ground Between Humans and Robots and senior writer at The New York Times, observed, “I am most concerned about the lack of algorithmic transparency. Increasingly we are a society that takes its life direction from the palm of our hands – our smartphones. Guidance on everything from what is the best Korean BBQ to who to pick for a spouse is algorithmically generated. There is little insight, however, into the values and motives of the designers of these systems.”
Fix the ‘organizational, societal and political climate we’ve constructed’
danah boyd, founder of Data & Society, commented, “An algorithm means nothing by itself. What’s at stake is how a ‘model’ is created and used. A model is comprised of a set of data (e.g., training data in a machine learning system) alongside an algorithm. The algorithm is nothing without the data. But the model is also nothing without the use case. The same technology can be used to empower people (e.g., identify people at risk) or harm them. It all depends on who is using the information to what ends (e.g., social services vs. police). Because of unhealthy power dynamics in our society, I sadly suspect that the outcomes will be far more problematic – mechanisms to limit people’s opportunities, segment and segregate people into unequal buckets, and leverage surveillance to force people into more oppressive situations. But it doesn’t have to be that way. What’s at stake has little to do with the technology; it has everything to do with the organizational, societal and political climate we’ve constructed.”
We have an algorithmic problem already: Credit scores
Henning Schulzrinne, Internet Hall of Fame member and professor at Columbia University, noted, “We already have had early indicators of the difficulties with algorithmic decision-making, namely credit scores. Their computation is opaque and they were then used for all kinds of purposes far removed from making loans, such as employment decisions or segmenting customers for different treatment. They leak lots of private information and are disclosed, by intent or negligence, to entities that do not act in the best interest of the consumer. Correcting data is difficult and time-consuming, and thus unlikely to be available to individuals with limited resources. It is unclear how the proposed algorithms address these well-known problems, given that they are often subject to no regulations whatsoever. In many areas, the input variables are either crude (and often proxies for race), such as home ZIP code, or extremely invasive, such as monitoring driving behavior minute-by-minute. Given the absence of privacy laws, in general, there is every incentive for entities that can observe our behavior, such as advertising brokers, to monetize behavioral information. At minimum, institutions that have broad societal impact would need to disclose the input variables used, how they influence the outcome and be subject to review, not just individual record corrections. An honest, verifiable cost-benefit analysis, measuring improved efficiency or better outcomes against the loss of privacy or inadvertent discrimination, would avoid the ‘trust us, it will be wonderful and it’s AI!’ decision-making.”
Algorithms ‘create value and cut costs’ and will be improved
Robert Atkinson, president of the Information Technology and Innovation Foundation, said, “Like virtually all past technologies, algorithms will create value and cut costs, far in excess of any costs. Moreover, as organizations and society get more experience with use of algorithms there will be natural forces toward improvement and limiting any potential problems.”
‘The goal should be to help people question authority’
Judith Donath of Harvard Berkman Klein Center for Internet & Society, replied, “Data can be incomplete, or wrong, and algorithms can embed false assumptions. The danger in increased reliance on algorithms is that is that the decision-making process becomes oracular: opaque yet unarguable. The solution is design. The process should not be a black box into which we feed data and out comes an answer, but a transparent process designed not just to produce a result, but to explain how it came up with that result. The systems should be able to produce clear, legible text and graphics that help the users – readers, editors, doctors, patients, loan applicants, voters, etc. – understand how the decision was made. The systems should be interactive, so that people can examine how changing data, assumptions, rules would change outcomes. The algorithm should not be the new authority; the goal should be to help people question authority.”
Do more to train coders with diverse world views
Amy Webb, futurist and CEO at the Future Today Institute, wrote, “In order to make our machines think, we humans need to help them learn. Along with other pre-programmed training datasets, our personal data is being used to help machines make decisions. However, there are no standard ethical requirements or mandate for diversity, and as a result we’re already starting to see a more dystopian future unfold in the present. There are too many examples to cite, but I’ll list a few: would-be borrowers turned away from banks, individuals with black-identifying names seeing themselves in advertisements for criminal background searches, people being denied insurance and health care. Most of the time, these problems arise from a limited worldview, not because coders are inherently racist. Algorithms have a nasty habit of doing exactly what we tell them to do. Now, what happens when we’ve instructed our machines to learn from us? And to begin making decisions on their own? The only way to address algorithmic discrimination in the future is to invest in the present. The overwhelming majority of coders are white and male. Corporations must do more than publish transparency reports about their staff – they must actively invest in women and people of color, who will soon be the next generation of workers. And when the day comes, they must choose new hires both for their skills and their worldview. Universities must redouble their efforts not only to recruit a diverse body of students –administrators and faculty must support them through to graduation. And not just students. Universities must diversify their faculties, to ensure that students see themselves reflected in their teachers.”
The impact in the short term will be negative; in the longer term it will be positive
Jamais Cascio, distinguished fellow at the Institute for the Future, observed, “The impact of algorithms in the early transition era will be overall negative, as we (humans, human society and economy) attempt to learn how to integrate these technologies. Bias, error, corruption and more will make the implementation of algorithmic systems brittle, and make exploiting those failures for malice, political power or lulz comparatively easy. By the time the transition takes hold – probably a good 20 years, maybe a bit less – many of those problems will be overcome, and the ancillary adaptations (e.g., potential rise of universal basic income) will start to have an overall benefit. In other words, shorter term (this decade) negative, longer term (next decade) positive.”
The story will keep shifting
Mike Liebhold, senior researcher and distinguished fellow at the Institute for the Future, commented, “The future effects of algorithms in our lives will shift over time as we master new competencies. The rates of adoption and diffusion will be highly uneven, based on natural variables of geographies, the environment, economies, infrastructure, policies, sociologies, psychology, and – most importantly – education. The growth of human benefits of machine intelligence will be most constrained by our collective competencies to design and interact effectively with machines. At an absolute minimum, we need to learn to form effective questions and tasks for machines, how to interpret responses and how to simply detect and repair a machine mistake.”
Make algorithms ‘comprehensible, predictable and controllable’
Ben Shneiderman, professor of computer science at the University of Maryland, wrote, “When well-designed, algorithms amplify human abilities, but they must be comprehensible, predictable and controllable. This means they must be designed to be transparent so that users can understand the impacts of their use and they must be subject to continuing evaluation so that critics can assess bias and errors. Every system needs a responsible contact person/organization that maintains/updates the algorithm and a social structure so that the community of users can discuss their experiences.”
In key cases, give the user control
David Weinberger, senior researcher at the Harvard Berkman Klein Center for Internet & Society, said, “Algorithmic analysis at scale can turn up relationships that are predictive and helpful even if they are beyond the human capacity to understand them. This is fine where the stakes are low, such as a book recommendation. Where the stakes are high, such as algorithmically filtering a news feed, we need to be far more careful, especially when the incentives for the creators are not aligned with the interests of the individuals or of the broader social goods. In those latter cases, giving more control to the user seems highly advisable.”
Conclusion
If you didn’t know what an algorithm was at the start of this article, hopefully, now, you have a more concrete understanding of the somewhat elusive term. As professional developers, it is important that we understand that the code we write can be analyzed and optimized, and it is important that we take the time to do this analysis of the performance of our code.
Any fun algorithm practice problems you’ve found? Perhaps a dynamic programming “knapsack problem”, or “drunken walk”? Or maybe you know of some best practices of recursion in Ruby that differ from the same functions implemented in Python. Share them in the comments!
The Fastest High Resolution Screen Printing Machines For Mass Production


